Kinesis Outage
On November 25, 2020, Amazon Web Services (AWS) experienced an outage in its Kinesis product that resulted in several cascading failures in several downstream products. The outage is known to have impact several well-known companies such as Adobe and Roku, at least, and countless customers. Amazon released a summary of the event providing initial details, including their observations, some technical details, and early remediation work.
I read through the summary and made several rough notes that I’ll share here. I’ve been revisiting my thoughts on Donella Meadows’ Systems Thinking in Practice so I’ll link to relevant content about system leverage points in the notes below.
Rough Notes
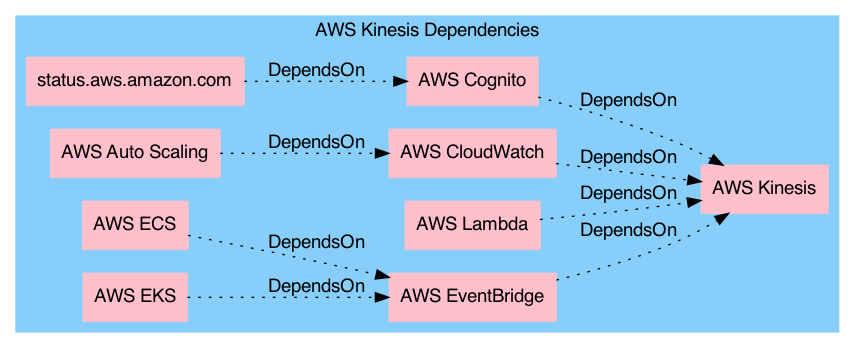
Kinesis powers a number of other services like Cognito, CloudWatch, and EventBridge.
- Cognito being degraded meant an inability for apps and services to
authenticate or generate temporary access tokens.
- A latent bug surfaced in Cognito.
- CloudWatch being degraded meant visibility into the health and behavior of
systems limits critical information that may be required to make decisions,
such as whether to deploy code.
- Reactive AutoScaling policies were delayed due to unavailable CloudWatch data.
- Lambda errors occurred because buffered metric data could not be sent to CloudWatch.
- EventBridge depends on Kinesis availability. EventBridge is relied on by
Elastic Container Service (ECS) and Elastic Kubernetes Service (EKS).
- During this outage, provisioning new resources, scaling existing resources, and de-provisioning resources in ECS and EKS was delayed.
- This, coupled with CloudWatch issues, can make for a perfect storm!
Adding capacity was a trigger.
- This occurred ahead of a major holiday. Was this a factor? In other words, was a decision made to add capacity in anticipation of increased load?
A resource limit (thread count on frontend servers) was exceeded.
- A response (future remediation) is to increase the stock size (size of CPU and memory constraints) to address another (thread count limit). The goal is to prevent impact on flow (communications between frontend and backend instances).
A number of immediate and forthcoming remediation items have been defined. Several architectural changes will be introduced, which themselves may trigger future outages. Or possibly surfaces other limits.
- As always, more alerting is needed.
- Frontend cluster thread count will be increased to support a greater buffer for future capacity additions.
- CloudWatch is being migrated to a separate, partitioned frontend fleet,
attempting to isolate it from similar strain.
- This work was already planned and underway but just got additional focus/priority.
- CloudWatch will implement a
buffer
by storing 3 hours’ worth of metrics in local storage.
- Ironically, in response to this issue, the Cognito team attempted to alleviate the issue by increasing capacity within their system to increase buffers.
- Outward communication via the Service Health Dashboard was hampered because the tool to do so relies on Cognito.
- A backup tool to update the Service Health Dashboard has fewer dependencies
but is manual and is less familiar to operators!
- What is the implication here regarding maintenance as practice?
- Support staff will be trained on the backup comms process.
Kinesis Dependencies
Based on the above notes, here’s a rough diagram of the services that have immediate or secondary (?) dependencies on Kinesis:
Tags